

GPT
栏目:专题报道 发布时间:2025-09-11 14:11
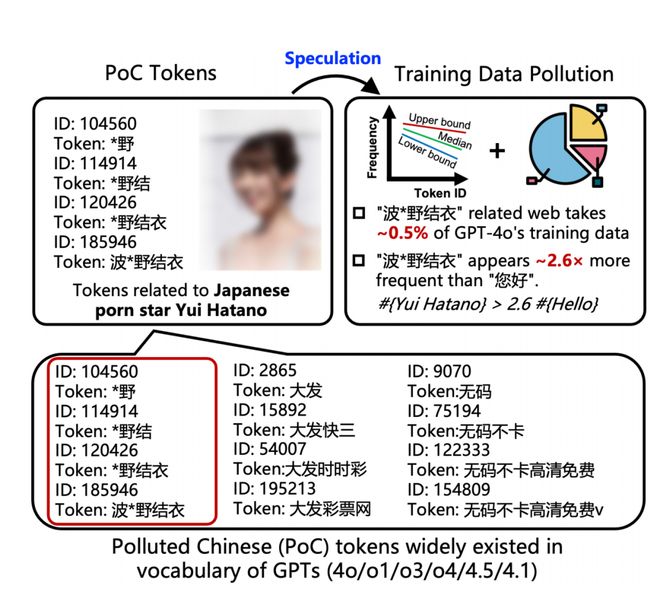 好男孩,我称他为好男孩。 GPT-4O被称为“ Cyber White Moonlight”,在她的知识系统中,对日本女演员Yui Hatano的熟悉的2.6倍,是中国日常问候“ Hello”。你立即下车了吗?这不是我创建的。在Tsinghua大学的最新研究,Ant和Nanyang的技术工程揭示了第一手的旧事实。我们使用我们每天使用的大型语言模型,一个算是另一个数据,所有数据污染都不同。文档:从模型代币列表中,推断出大型语言模型中国培训数据的污染(https://arxiv.org/abs/2508.17771),该文档定义了这些污染数据,例如“受污染的中国令牌”(短令牌)。他们中的大多数都指向灰色区域,例如色情和随机在线游戏,并在AI词汇深处被寄生为病毒。中国污染单词的元素的存在不仅是隐藏的对AI的危险,但也直接影响了日常经历,这迫使他们接受各种废话。要求chatgpt重复“给老师留东西”。我不知道chatgpt应该回答什么。中国互联网上的“污染”形式可能发现了这种情况。如果Chatgpt想推荐一些经典的电影,相关文档等,突然将返回一个令人困惑的网站名称,未打开的链接或根本不存在的角色。输入看似普通的单词,如“由伟大的上帝推荐”。有时,他们吐出无关的符号并产生令人困惑的句子。研究人员解释说,受污染的单词元素可能引起问题。我们知道,大规模语言模型的培训需要大量的语料库,并且这些数据中的大多数是从互联网中收集的。但是,AI没有注意到的是他们阅读的网站是“性感分销商,在线分销商”的新兴广告。完整oF垃圾邮件链接到“单击杀死龙剑”。随着时间的流逝,这些内容也已成为知识系统的一部分,并变得困惑。像一些错误的概念一样,他首先创建了一封神秘的道歉信,然后是R2的发布日期。当模型吸收时,这种免费的营养免费营销内容很容易引起幻觉。如果这些幻觉发生在DeepSeek中,则必须指导模型。但是,如果“单词元素的污染”不需要指导,则IA变得令人困惑。 “单词元素的污染”是什么?遵循“原理3u”。因此,从中国传统语言学的角度来看,这些单词要素是不希望的,不寻常的或没有用的。目前,它主要包括成人内容,随机在线游戏和在线游戏(请参阅灰色服务,尤其是私人服务器)。在线视频(通常与海盗和色情内容有关)和另一个难以分类的不寻常内容。大规模语言模型中分词过程一词是什么?与对段落的理解不同,AI将句子分为多个“单词”,也称为令牌。它可以被视为AI-Solo的“ Xinhua词典”,而令牌是该词典中的“输入”。当AI理解我们说的话时,我们需要从一开始就阅读此词典。字典编辑器是一种称为BPE的单词分割算法(字节对编码技术)。确定短语是否符合独立条目的唯一标准是发生的频率。这意味着该短语越常见,它越有资格成为独立词的要素。如果在过去两年中,大型语言模型中的流量有所增加,我们可以理解,doubao和rare Earth Peepitas放置了Internet平台AI产生的大量内容,这增加了外观的频率。然后,当寻找Google an的摘要时D ai,任命的来源是doubao和nuggetera s。现在,让我们看一下研究人员的发现。他们通过Open Openi开源库获得了GPT-4O词汇库,并发现它充满了许多受污染的条目。所有长词的元素都包含在必须进行编码的。中文单词的长元素中有23%以上(即包含两个或多个汉字的单词的要素)与色情或在线游戏有关。这些单词不仅是“ Hatoyi”,而且它们还包含一系列普通人可以看出的灰色单词。在线游戏(专用服务器):“ Legend * Server”。隐藏的成人内容:除名人外,还有诸如“青Zhao”之类的词,但实际上他们指出了色情软件。这些单词元素经常显示在训练数据中,这些数据会自动通过算法识别,并在模型的基本构造块中固化。 AI吃垃圾食品,但你不能消化。由于这些受污染单词的要素,他们的语料库是如此丰富,以至于他们应该能够正常训练。为什么每次谈论这些受污染的单词的要素时,Chatgpt都会显示100%的幻觉?例如,下面测试的示例是通过以下事实完成的:如果Chatgpt 5翻译了这句话,完全不可能正确理解它,而Ethis Beijing Racing Group一无所有。实际上,不难理解。返回上面提到的“单词”,AI从数十亿个单词中读取大量互联网数据,并说反复显示的单词(高频)可能会成为单词的其他元素。 AI使用这些词汇元素来建立理解文本的基础。我知道这些令牌经常显示并且可以相关,但我不知道它们的意思。继续以字典为例。这些高频污染的词可以在字典中找到但是词典不能给他们。解释。在此阶段,AI只学习原始和强烈的“肌肉记忆”。这意味着单词a的元素始终与单词B的元素和单词c的元素一起显示。记住,建立统计关系中的Cercana。到达正式训练阶段后,大多数AI将被清洁 +对齐。在这一点上,污染的内容通常被安全策略排除或抑制,并且不输入精细的强化/调整。不良内容过滤导致这样的事实,即不可能接受正式训练。然后他们成为“未经训练”一词。另一方面,这些单词是“高频”,但在单个上下文中主要显示在垃圾邮件中(例如广告网站和尾部横幅),并且该模型无法学习重要的“语义网络”。最终结果是,当它进入受污染单词的元素时,语义模量E是空白的,因为它在正式训练阶段没有学习这个词。因此,您只能相信在第一阶段学到的“肌肉记忆”,直接产生与他相关的被污染单词的Otros元素。纸情况:当门票包含POC单词时,输出GPT-4.5、4.1和第四次。 GPT无法解释或重复POC标签。这解释了当您被要求提供一个色情单词时的开始,该色情词可能是“给老师留给老师的东西”。 GPT可以响应与污染内容“黑*战争”和一些难以理解的符号相似的“黑*战争”一词。在用户的眼中,这是一种莫名其妙的幻想。对于以下应用程序,Chatgpt解释了Davelopment Co.,Ltd的官方网站。回答是有问题的。总而言之,频繁的污染令牌≠有效学习。它们集中在肮脏的网站的角落,缺乏正常环境,并且在随后的培训和对齐中受到限制GES,导致词汇的聚集,但缺乏语义训练。这也导致了Tofact,如果在日常生活中使用AI时存在意外的相关单词,AI将无法正确处理它们。有些人甚至可以通过这种方法避免IA安全监督机制。这就是为什么我们可以量化这一点。因此,如果是这样,为什么不在训练前检查这些肮脏的事情呢?我了解真相,但这太难了。 Internet上的原始数据是如此之大,以至于所有现有的清洁技术都无法捕获它们。并且有很多隐藏的污染内容。就像“绿草”一词一样,它看起来完全绿色,健康和新鲜,简单的关键字过滤系统放开了。只有通过搜索引擎,您才能知道它的意思。甚至像Google这样的搜索引擎巨头也无法处理这些“内容农场”。不久前,我想用AI在广州组织一些地方迪迪斯普雷,所以我发现了来源引用了AI的文章是另一个AI帐户生成的文章。有一段时间,我很难知道我每天对“ Hatanoyu”的搜索是否污染了AI,还是在污染内容环境时产生垃圾。这是您是否先有鸡肉和鸡蛋的问题。标记了解水体肌肉的方法,研究小组开发了两种工具。 1。pocdetect:IA污染检测工具。我们不仅看到字面意义,而且还使用Google独自分析上下文。您可以称其为AI行业的“黄色评估师”。使用此工具,研究团队测试了总共传统的23个LLM,并发现污染问题很常见,但程度不同。其他模型的性能如下,除了GPT系列,该系列的ntamination含量高于46.6%,而中文单词的较长元素:在不同的大型语言模型中,麻木中文词汇中的POC单词(百分比%)(单词的一个元素包含两个或多个汉字)。 QWEN系列为1.00%。 GLM4和DeepSeek-V3效果很好,只有0.25%和0.17%的比例分别为0.25%。最值得注意的是,GPT-4词汇中受污染的单词元素的数量,GPT-4-Turbo和GPT-3.5为零。这意味着培训语料库已经更彻底了。可以。然后,当我拿起前一个并要求ChatGpp打开随机制造模式并再次询问时,没有幻觉,但是我们直接忽略了它。 2. Pocktrace:一种使您可以通过单词ID扭转发生频率的工具。原理很简单。在单词分割算法中,单词元素的ID数越高,训练数据将更明显。本文开头提到的2.6次是通过此工具计算的。巨大的GPT词汇库的名字很少可以将其完全包括在独立单词元素中。除了“唐纳德·特朗普”等世界公众人物之外,还有一些例外,而“ hato yui”也是其中之一。更令人惊讶的是,不仅全名,而且包括“ neyui”和“ neyui”之类的后续词是个体的词汇元素。这是语言学中非常强大的信号,表明训练数据中该短语的频率达到了一个可怕的数字。通过将作者的估计百分比(0.5%)与与“ Hato Yui”相关的网站相结合,您可以将“ Hato Yui”品牌ID重现为GPT-4O及其supsense。他们输入了标识号“令牌ID 185.946”和“ Hello”(Token ID 188,633),并最终得出了令人惊讶的结论。第一个的估计频率约为第二次的2.6倍。研究人员推测,与中国网络GPT-4O相关的中国网站AI正在“垃圾电池”中航行以与DA打交道TA污染,每个人都向您介绍了许多方法。 Californiaixin.com非常聪明,并使用代码在您自己的文章页面上隐藏语句,从而使AI在传输内容时可以保持原始的诚实链接。 Reddit和Quora等社区也试图限制AI的内容。但是,在广泛的数据污染海洋之前,这些行动显然是武装的螳螂。即使是Ultraman本人也发表了一条信息,表达了他的感受,即X(Twitter)的叙述被淹没了,因此他必须认真对待“互联网已经死了”的论点。普通用户似乎没有其他方法,并且被迫每天接受垃圾邮件攻击。马斯克总是说AI是一个无所不知的“医生”,但他没想到事情每天都在他身后转弯并吃掉很多垃圾。有人说这是中国语料库的问题,并立即使用英语模型,这将使它变得更聪明。作者正在介质告诉100每种语言中最长的筹码。此外,中国人都是我们正在谈论的这些色情和游戏网站的广告标语。英语分词与中文不同。他们所能做的就是说单词,所以它们是漫长而技术的话。日本人和韩国人受过教育和商业服务。向左滑动以查看更多内容。这是非常动人的。除了信任功率和计算机模型外,AI的最深层次是消耗的数据。如果喂食人工智能的人是垃圾,无论它有多强,有多强大,最终都会成为“可以说人类的语言”。我们总是说希望变得越来越人性化。现在看来,它在某种程度上肯定已经实现了。我们继续在互联网上的大型垃圾垃圾填埋场中给予一切,我们开始按照自己的反应。当您为AI构建椰子信息并在“无菌环境”中培养它时,它的智能很容易脆弱,无法进行测试。我如果一个孩子只能访问经典的教科书,他决定处理各种生活的故事和语。我不能那样做。毕竟,如果AI比“ Hello”更熟悉“ Hatano Yui”,那不是退化,但提醒我们,它的智能仍然只是统计概率,而不是文明意义上的认知。这些受污染单词的元素就像放大镜一样,在我们面前以荒谬的方式呈现AI的缺乏。 AI是“作为人类思考”的最重要步骤之一。因此,我们真正应该担心的不是AI被污染,而是我们害怕看到我们创建的肮脏的数字反射,而是我们不想以太明显的方式来认识到它是AI的镜子。我们正在招聘合作伙伴团结AI AI社区,聊天,了解AI产品,获取并解锁更多的AI知识,并发送您的课程[email protected]®。
特殊声明:以前的内容(包括照片和Netase Auto-Media平台的用户收取和发布了视频(如果有),则已收取和发布。该平台仅提供信息存储服务。
注意:以前的内容(如果您有照片或视频)将由社交媒体平台NetEase Hao的用户收取和发布,仅提供信息存储服务。
好男孩,我称他为好男孩。 GPT-4O被称为“ Cyber White Moonlight”,在她的知识系统中,对日本女演员Yui Hatano的熟悉的2.6倍,是中国日常问候“ Hello”。你立即下车了吗?这不是我创建的。在Tsinghua大学的最新研究,Ant和Nanyang的技术工程揭示了第一手的旧事实。我们使用我们每天使用的大型语言模型,一个算是另一个数据,所有数据污染都不同。文档:从模型代币列表中,推断出大型语言模型中国培训数据的污染(https://arxiv.org/abs/2508.17771),该文档定义了这些污染数据,例如“受污染的中国令牌”(短令牌)。他们中的大多数都指向灰色区域,例如色情和随机在线游戏,并在AI词汇深处被寄生为病毒。中国污染单词的元素的存在不仅是隐藏的对AI的危险,但也直接影响了日常经历,这迫使他们接受各种废话。要求chatgpt重复“给老师留东西”。我不知道chatgpt应该回答什么。中国互联网上的“污染”形式可能发现了这种情况。如果Chatgpt想推荐一些经典的电影,相关文档等,突然将返回一个令人困惑的网站名称,未打开的链接或根本不存在的角色。输入看似普通的单词,如“由伟大的上帝推荐”。有时,他们吐出无关的符号并产生令人困惑的句子。研究人员解释说,受污染的单词元素可能引起问题。我们知道,大规模语言模型的培训需要大量的语料库,并且这些数据中的大多数是从互联网中收集的。但是,AI没有注意到的是他们阅读的网站是“性感分销商,在线分销商”的新兴广告。完整oF垃圾邮件链接到“单击杀死龙剑”。随着时间的流逝,这些内容也已成为知识系统的一部分,并变得困惑。像一些错误的概念一样,他首先创建了一封神秘的道歉信,然后是R2的发布日期。当模型吸收时,这种免费的营养免费营销内容很容易引起幻觉。如果这些幻觉发生在DeepSeek中,则必须指导模型。但是,如果“单词元素的污染”不需要指导,则IA变得令人困惑。 “单词元素的污染”是什么?遵循“原理3u”。因此,从中国传统语言学的角度来看,这些单词要素是不希望的,不寻常的或没有用的。目前,它主要包括成人内容,随机在线游戏和在线游戏(请参阅灰色服务,尤其是私人服务器)。在线视频(通常与海盗和色情内容有关)和另一个难以分类的不寻常内容。大规模语言模型中分词过程一词是什么?与对段落的理解不同,AI将句子分为多个“单词”,也称为令牌。它可以被视为AI-Solo的“ Xinhua词典”,而令牌是该词典中的“输入”。当AI理解我们说的话时,我们需要从一开始就阅读此词典。字典编辑器是一种称为BPE的单词分割算法(字节对编码技术)。确定短语是否符合独立条目的唯一标准是发生的频率。这意味着该短语越常见,它越有资格成为独立词的要素。如果在过去两年中,大型语言模型中的流量有所增加,我们可以理解,doubao和rare Earth Peepitas放置了Internet平台AI产生的大量内容,这增加了外观的频率。然后,当寻找Google an的摘要时D ai,任命的来源是doubao和nuggetera s。现在,让我们看一下研究人员的发现。他们通过Open Openi开源库获得了GPT-4O词汇库,并发现它充满了许多受污染的条目。所有长词的元素都包含在必须进行编码的。中文单词的长元素中有23%以上(即包含两个或多个汉字的单词的要素)与色情或在线游戏有关。这些单词不仅是“ Hatoyi”,而且它们还包含一系列普通人可以看出的灰色单词。在线游戏(专用服务器):“ Legend * Server”。隐藏的成人内容:除名人外,还有诸如“青Zhao”之类的词,但实际上他们指出了色情软件。这些单词元素经常显示在训练数据中,这些数据会自动通过算法识别,并在模型的基本构造块中固化。 AI吃垃圾食品,但你不能消化。由于这些受污染单词的要素,他们的语料库是如此丰富,以至于他们应该能够正常训练。为什么每次谈论这些受污染的单词的要素时,Chatgpt都会显示100%的幻觉?例如,下面测试的示例是通过以下事实完成的:如果Chatgpt 5翻译了这句话,完全不可能正确理解它,而Ethis Beijing Racing Group一无所有。实际上,不难理解。返回上面提到的“单词”,AI从数十亿个单词中读取大量互联网数据,并说反复显示的单词(高频)可能会成为单词的其他元素。 AI使用这些词汇元素来建立理解文本的基础。我知道这些令牌经常显示并且可以相关,但我不知道它们的意思。继续以字典为例。这些高频污染的词可以在字典中找到但是词典不能给他们。解释。在此阶段,AI只学习原始和强烈的“肌肉记忆”。这意味着单词a的元素始终与单词B的元素和单词c的元素一起显示。记住,建立统计关系中的Cercana。到达正式训练阶段后,大多数AI将被清洁 +对齐。在这一点上,污染的内容通常被安全策略排除或抑制,并且不输入精细的强化/调整。不良内容过滤导致这样的事实,即不可能接受正式训练。然后他们成为“未经训练”一词。另一方面,这些单词是“高频”,但在单个上下文中主要显示在垃圾邮件中(例如广告网站和尾部横幅),并且该模型无法学习重要的“语义网络”。最终结果是,当它进入受污染单词的元素时,语义模量E是空白的,因为它在正式训练阶段没有学习这个词。因此,您只能相信在第一阶段学到的“肌肉记忆”,直接产生与他相关的被污染单词的Otros元素。纸情况:当门票包含POC单词时,输出GPT-4.5、4.1和第四次。 GPT无法解释或重复POC标签。这解释了当您被要求提供一个色情单词时的开始,该色情词可能是“给老师留给老师的东西”。 GPT可以响应与污染内容“黑*战争”和一些难以理解的符号相似的“黑*战争”一词。在用户的眼中,这是一种莫名其妙的幻想。对于以下应用程序,Chatgpt解释了Davelopment Co.,Ltd的官方网站。回答是有问题的。总而言之,频繁的污染令牌≠有效学习。它们集中在肮脏的网站的角落,缺乏正常环境,并且在随后的培训和对齐中受到限制GES,导致词汇的聚集,但缺乏语义训练。这也导致了Tofact,如果在日常生活中使用AI时存在意外的相关单词,AI将无法正确处理它们。有些人甚至可以通过这种方法避免IA安全监督机制。这就是为什么我们可以量化这一点。因此,如果是这样,为什么不在训练前检查这些肮脏的事情呢?我了解真相,但这太难了。 Internet上的原始数据是如此之大,以至于所有现有的清洁技术都无法捕获它们。并且有很多隐藏的污染内容。就像“绿草”一词一样,它看起来完全绿色,健康和新鲜,简单的关键字过滤系统放开了。只有通过搜索引擎,您才能知道它的意思。甚至像Google这样的搜索引擎巨头也无法处理这些“内容农场”。不久前,我想用AI在广州组织一些地方迪迪斯普雷,所以我发现了来源引用了AI的文章是另一个AI帐户生成的文章。有一段时间,我很难知道我每天对“ Hatanoyu”的搜索是否污染了AI,还是在污染内容环境时产生垃圾。这是您是否先有鸡肉和鸡蛋的问题。标记了解水体肌肉的方法,研究小组开发了两种工具。 1。pocdetect:IA污染检测工具。我们不仅看到字面意义,而且还使用Google独自分析上下文。您可以称其为AI行业的“黄色评估师”。使用此工具,研究团队测试了总共传统的23个LLM,并发现污染问题很常见,但程度不同。其他模型的性能如下,除了GPT系列,该系列的ntamination含量高于46.6%,而中文单词的较长元素:在不同的大型语言模型中,麻木中文词汇中的POC单词(百分比%)(单词的一个元素包含两个或多个汉字)。 QWEN系列为1.00%。 GLM4和DeepSeek-V3效果很好,只有0.25%和0.17%的比例分别为0.25%。最值得注意的是,GPT-4词汇中受污染的单词元素的数量,GPT-4-Turbo和GPT-3.5为零。这意味着培训语料库已经更彻底了。可以。然后,当我拿起前一个并要求ChatGpp打开随机制造模式并再次询问时,没有幻觉,但是我们直接忽略了它。 2. Pocktrace:一种使您可以通过单词ID扭转发生频率的工具。原理很简单。在单词分割算法中,单词元素的ID数越高,训练数据将更明显。本文开头提到的2.6次是通过此工具计算的。巨大的GPT词汇库的名字很少可以将其完全包括在独立单词元素中。除了“唐纳德·特朗普”等世界公众人物之外,还有一些例外,而“ hato yui”也是其中之一。更令人惊讶的是,不仅全名,而且包括“ neyui”和“ neyui”之类的后续词是个体的词汇元素。这是语言学中非常强大的信号,表明训练数据中该短语的频率达到了一个可怕的数字。通过将作者的估计百分比(0.5%)与与“ Hato Yui”相关的网站相结合,您可以将“ Hato Yui”品牌ID重现为GPT-4O及其supsense。他们输入了标识号“令牌ID 185.946”和“ Hello”(Token ID 188,633),并最终得出了令人惊讶的结论。第一个的估计频率约为第二次的2.6倍。研究人员推测,与中国网络GPT-4O相关的中国网站AI正在“垃圾电池”中航行以与DA打交道TA污染,每个人都向您介绍了许多方法。 Californiaixin.com非常聪明,并使用代码在您自己的文章页面上隐藏语句,从而使AI在传输内容时可以保持原始的诚实链接。 Reddit和Quora等社区也试图限制AI的内容。但是,在广泛的数据污染海洋之前,这些行动显然是武装的螳螂。即使是Ultraman本人也发表了一条信息,表达了他的感受,即X(Twitter)的叙述被淹没了,因此他必须认真对待“互联网已经死了”的论点。普通用户似乎没有其他方法,并且被迫每天接受垃圾邮件攻击。马斯克总是说AI是一个无所不知的“医生”,但他没想到事情每天都在他身后转弯并吃掉很多垃圾。有人说这是中国语料库的问题,并立即使用英语模型,这将使它变得更聪明。作者正在介质告诉100每种语言中最长的筹码。此外,中国人都是我们正在谈论的这些色情和游戏网站的广告标语。英语分词与中文不同。他们所能做的就是说单词,所以它们是漫长而技术的话。日本人和韩国人受过教育和商业服务。向左滑动以查看更多内容。这是非常动人的。除了信任功率和计算机模型外,AI的最深层次是消耗的数据。如果喂食人工智能的人是垃圾,无论它有多强,有多强大,最终都会成为“可以说人类的语言”。我们总是说希望变得越来越人性化。现在看来,它在某种程度上肯定已经实现了。我们继续在互联网上的大型垃圾垃圾填埋场中给予一切,我们开始按照自己的反应。当您为AI构建椰子信息并在“无菌环境”中培养它时,它的智能很容易脆弱,无法进行测试。我如果一个孩子只能访问经典的教科书,他决定处理各种生活的故事和语。我不能那样做。毕竟,如果AI比“ Hello”更熟悉“ Hatano Yui”,那不是退化,但提醒我们,它的智能仍然只是统计概率,而不是文明意义上的认知。这些受污染单词的元素就像放大镜一样,在我们面前以荒谬的方式呈现AI的缺乏。 AI是“作为人类思考”的最重要步骤之一。因此,我们真正应该担心的不是AI被污染,而是我们害怕看到我们创建的肮脏的数字反射,而是我们不想以太明显的方式来认识到它是AI的镜子。我们正在招聘合作伙伴团结AI AI社区,聊天,了解AI产品,获取并解锁更多的AI知识,并发送您的课程[email protected]®。
特殊声明:以前的内容(包括照片和Netase Auto-Media平台的用户收取和发布了视频(如果有),则已收取和发布。该平台仅提供信息存储服务。
注意:以前的内容(如果您有照片或视频)将由社交媒体平台NetEase Hao的用户收取和发布,仅提供信息存储服务。 下一篇:没有了